Dask Distributed
Overview
Tutorial: 1 Hour
- Objectives:
Learn about Dask Distributed.
Dask Distributed is a powerful extension of Dask that enables parallel and distributed computing across multiple machines or a cluster of machines. It allows users to scale their Dask computations beyond a single machine by distributing tasks across a cluster, utilizing multiple workers. Dask Distributed provides a distributed scheduler, which manages the execution of tasks, handles dependencies, and balances workloads efficiently. With Dask Distributed, users can easily scale from local machine execution to large-scale, high-performance clusters, making it ideal for large datasets, high computational workloads, and complex machine learning or data processing tasks. It integrates seamlessly with other Dask collections like Dask DataFrame, Dask Array, and Dask Delayed.

Users interact with the scheduler through a Python session by submitting tasks using client.submit(function, *args, **kwargs) for custom control or via Dask collections like dask.array and dask.dataframe. The dynamic asynchronous task scheduler that coordinates multiple worker processes across machines and handles requests from multiple clients. The scheduler tracks tasks as a constantly evolving directed acyclic graph (DAG), where each task is a Python function operating on objects, potentially the results of other tasks. This graph grows with user-submitted computations and shrinks as tasks are completed or discarded.
Local cluster
A local cluster in Dask refers to running Dask’s distributed computing framework on your local machine, using multiple processes or threads for parallelism without needing a distributed system or cluster of remote machines. It allows you to take advantage of multiple CPU cores on a single machine to parallelize tasks and scale computations for large datasets.
1from dask.distributed import Client, LocalCluster
2
3# Set up a local cluster with a specific number of workers
4cluster = LocalCluster(n_workers=4)
5
6# Connect to the local cluster
7client = Client(cluster)
8
9# Submit a task to the local cluster
10future = client.submit(lambda x: x + 1, 10)
11
12# Get the result once the task is complete
13result = future.result()
Explanation
n_workers is a parameter of the LocalCluster class that specifies the number of worker processes to create in the local Dask cluster. Each worker process is responsible for executing tasks independently, allowing parallel computation across multiple cores on the same machine.
PBS cluster
HPC systems typically use a job scheduler like SLURM, PBS, or SGE to manage compute resources. Gadi uses a modified version of PBS. Each job request specifies the number of nodes, cores, memory, and wall time required for a computation. Dask integrates with these schedulers to distribute workloads efficiently across the allocated resources.
1import dask.distributed as dd
2from dask.distributed import Client, LocalCluster, progress
3from dask_jobqueue import PBSCluster
4from dask.distributed import get_worker
5import os
6
7os.environ['DASK_PYTHON'] = '/scratch/vp91/Training-Venv/parallel_python/bin/python3'
Explanation
It is very important to make sure all element of Dask use the same Python version.
1setup_commands = ["module load python3/3.11.0", "module load cmake/3.16.2", "source /scratch/abc/Training-Venv/parallel_python/bin/activate"]
Explanation
The first two commands load the required modules while last cpmmand activates the Python environment. This ensures that all the node in the cluster used the same module and also the same Python environment.
1extra = ['-q normal',
2 '-P vp91',
3 '-l ncpus=48',
4 '-l mem=192GB']
Explanation
Gadi uses a seperate falgs than an out-of-the-box PBS scheduler. So these different flags and their corresponding values are given as extra instructions.
1cluster = PBSCluster(walltime="00:20:00",
2 cores=48,
3 memory="192GB",
4 shebang='#!/usr/bin/env bash',
5 job_extra_directives=extra,
6 local_directory='$TMPDIR',
7 job_directives_skip=["select"],
8 interface="ib0",
9 job_script_prologue=setup_commands,
10 python=os.environ["DASK_PYTHON"])
The code sets up a Dask cluster on an HPC system using PBS as the job scheduler. It configures each job to use 48 CPU cores, 192GB of memory, and a 20-minute runtime, with additional customizations like temporary storage ($TMPDIR) and high-speed network communication (ib0). The cluster launches Dask workers via PBS jobs, enabling distributed and parallel computations, and connects to the workers using a Python client.
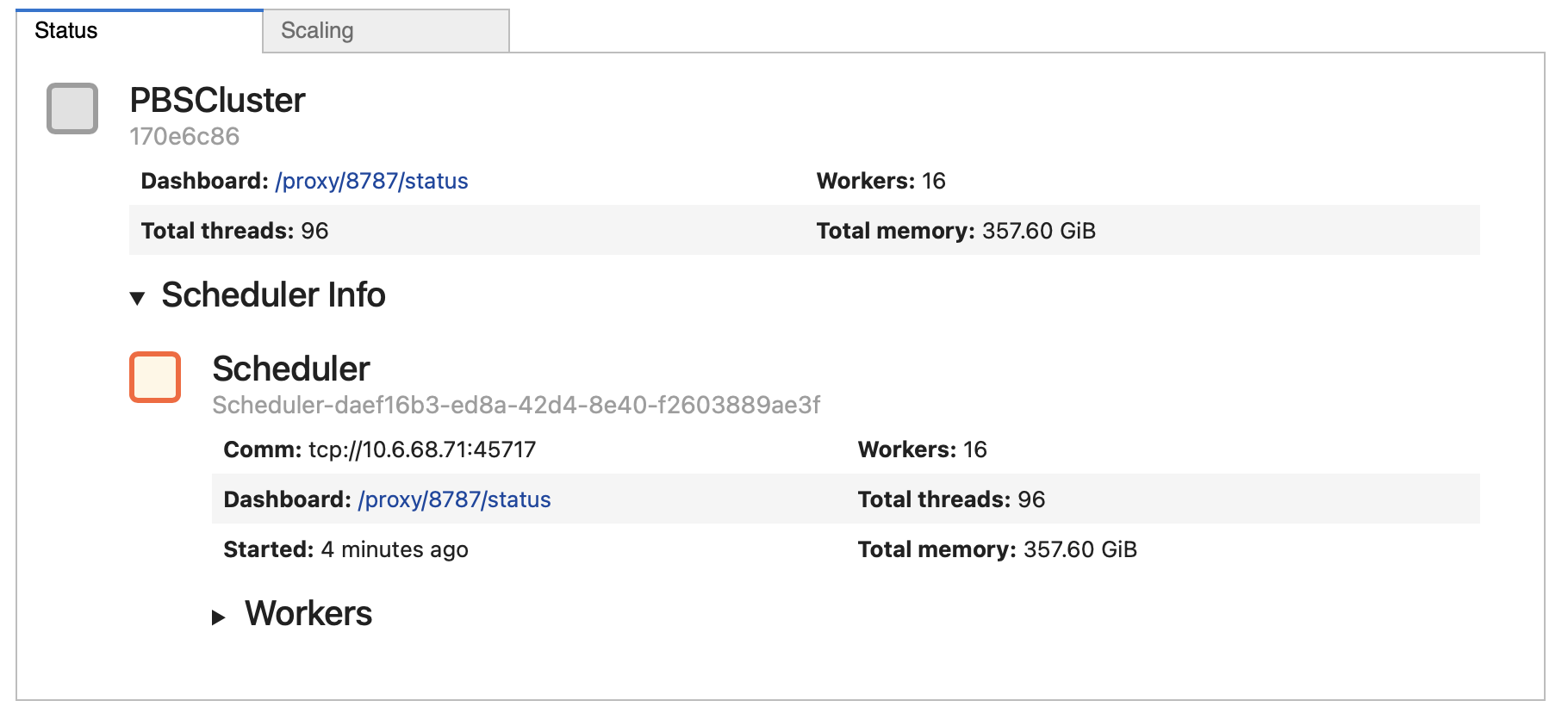
Explanation
walltime`: Specifies the maximum duration for each job submitted to the PBS scheduler. In this case, each job will run for 20 minutes. Format: HH:MM:SS.
cores: Specifies the number of CPU cores allocated per job. Each Dask worker will utilize 48 cores for parallel processing.
memory: Specifies the total memory available for each job. Each worker will use up to 192 GB of RAM.
shebang: Defines the shebang line at the top of the job script, indicating that the script should be executed using bash. This is important for environments where custom shells or paths are used.
job_extra_directives: Passes additional PBS directives (specified in the extra variable) to customize the job script further.
local_directory: Specifies a local directory on the compute node to store temporary files for Dask workers.
job_directives_skip: Skips generating certain PBS directives automatically. Here, the select directive is omitted because it might conflict with how resources are allocated in the cluster. Useful for more fine-grained control over the job script.
interface: Specifies the network interface for inter-worker communication. ib0 typically refers to an InfiniBand interface, used for high-speed, low-latency networking in HPC systems.
job_script_prologue: Defines a list of shell commands (stored in setup_commands) to be executed before starting the Dask worker processes.
python=os.environ[“DASK_PYTHON”] : Specifies the Python executable to be used for running Dask worker processes.
1cluster.scale(jobs=2)
The code cluster.scale(jobs=2) dynamically scales the Dask cluster to have 2 active jobs running on the HPC system.
Explanation
The above code dynamically adjust the computational resources based on workload requirements. Each “job” corresponds to a PBS job (or worker group) submitted to the scheduler. The number of workers (and resources like cores and memory) within each job is determined by the configuration provided when the cluster was created (e.g., cores=48, memory=”192GB” in PBSCluster).
1client = Client(cluster)
Explanation
The code client = Client(cluster) connects a Dask client to the specified cluster, enabling interaction with the Dask scheduler and workers. Once connected, the client acts as a central interface to interact with the cluster.
1def slow_increment(x):
2 return x+1
3
4futures = client.submit(slow_increment, 5000)
Explanation
client.submit() sends the slow_increment function and its argument (5000) to the Dask cluster for computation. client.submit() is non-blocking, meaning it immediately returns a future object without waiting for the computation to finish. The task is assigned to the first available worker that is idle or has the resources to execute it.
Key Points
Dask distributed uses an event-driven scheduler to manage task execution across multiple workers while respecting task dependencies.
Dask scales from a single machine to a distributed cluster, adapting to changing workloads.
Tasks and workers communicate asynchronously for efficient execution and data transfer.